
(Some might argue that the co-worker's response should be labeled PL3 instead of PL2, since he uses 「でしょ」 instead of 「だろ」 or 「だろう」)
Long out of print, digitized archives of all 70 issues float around the Internet; one kind soul has been hosting the first 30 issues for ages.
However, these days, you can turn almost any Japanese source image into a Mangajin-like smorgasbord of information thanks to two open source, portable apps from Christopher Brochtrup:
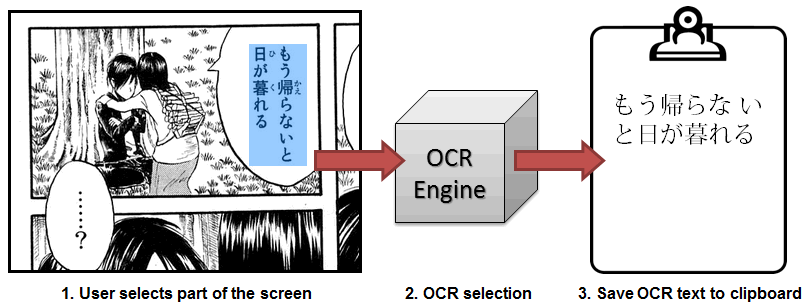
Capture2Text "enables users to quickly OCR a portion of the screen using a keyboard shortcut. The resulting text will be saved to the clipboard by default. Supports 90+ languages including Chinese, English, French, German, Japanese, and Spanish. Portable and does not require installation. See http://capture2text.sourceforge.net for details."
JGlossator "can create a gloss for Japanese text complete with de-inflected expressions, readings, audio pronunciation, example sentences, pitch accent, word frequency, kanji information, and grammar analysis. See http://jglossator.sourceforge.net/ for more information and screenshots. Inspired by Translation Aggregator, but aimed primarily at people learning Japanese."
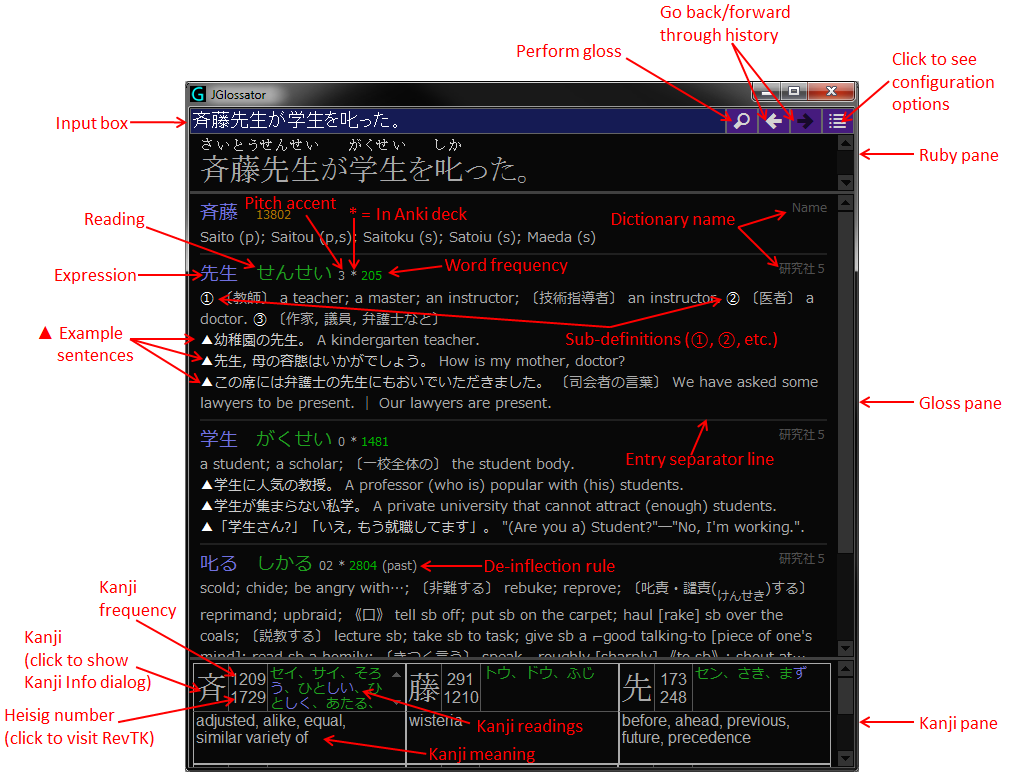
The two work seamlessly together; here is a video of them in action.
manga-ocr: "Optical character recognition for Japanese text, with the main focus being Japanese manga"
yomitan: "Pop-up dictionary browser extension for language learning. Successor to Yomichan."
Poricom: "Optical character recognition in manga images. Manga OCR desktop application"
mokuro: "Read Japanese manga inside browser with selectable text."
JP Lazy Guide "is for:
/windows | May 28, 2016