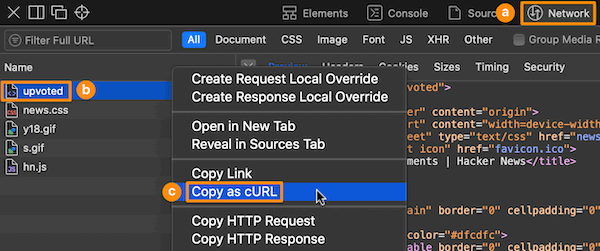
for i in {7..11}; do
curl --compressed "https://news.ycombinator.com/upvoted?id=miles&comments=t&p=${i}" \
-X 'GET' \
-H 'Cookie: user=miles&XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' \
-H 'Accept-Encoding: gzip, deflate, br' \
-H 'Host: news.ycombinator.com' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15' \
-H 'Accept-Language: en-us' \
-H 'Referer: https://news.ycombinator.com/' \
-H 'Connection: keep-alive' -o ${i}.htm
; sleep 5; done
The URL for the first page of upvoted comments looks like https://news.ycombinator.com/upvoted?id=miles&comments=t, while subsequent pages have &p=# appended, e.g., https://news.ycombinator.com/upvoted?id=miles&comments=t&p=2.
HN rate limits requests, so throttling is necessary (otherwise, you will receive a "Sorry, we're not able to serve your requests this quickly." response and ultimately your IP address may be banned). While wget offers a --wait=seconds option, the closest curl comes is --limit-rate <speed>, which sadly did not prevent the warning from occurring when sequencing, even at rates as slow as 1000 bytes per second, hence the for loop with delay. See Implement wget's --wait, --random-wait #5406.
Otherwise, files are saved as compressed, necessitating something along the lines of gzip -d -f -S "" * to decompress. [1, 2, 3, 4]
Without -H 'Accept-Encoding: gzip, deflate, br' \, 5-6 times the bandwidth is used to download uncompressed HTML.